[강화시스터즈 2기] 강화학습 개론
강화학습
강화학습의 개념
머신러닝은 크게 지도학습, 비지도학습, 강화학습으로 분류된다.
강화학습은 에이전트(Agent)가 환경(Environment)과 상호작용하면서 보상(Reward)을 최대화할 수 있도록 스스로 학습하는 과정이다. 보상을 통해 주어진 상황에서 어떤 행동을 취할 것인지를 학습한다. 이 보상은 직접적인 답은 아니지만 간접적인 정답의 역할을 한다.
강화학습의 목적
에이전트가 환경을 탐색하면서 얻는 보상들의 합을 최대화하는 최적의 정책을 학습하는 것이다.
강화학습 구성요소
에이전트와 환경
- 에이전트는 환경에 대해 사전지식이 없는 상태에서 학습을 한다. 에이전트는 어떤 행동을 할 것인지 결정하는 의사 결정자이며, 자신의 행동과 행동의 결과를 보상을 통해 학습하면서 어떤 행동을 해야 좋은 결과를 얻게 되는지 알게 된다.
- 환경은 에이전트가 목표를 달성하기 위해 탐색하고 학습해야 할 대상이다. 에이전트의 행동에 반응하여 다음 상태와 보상을 제공한다.
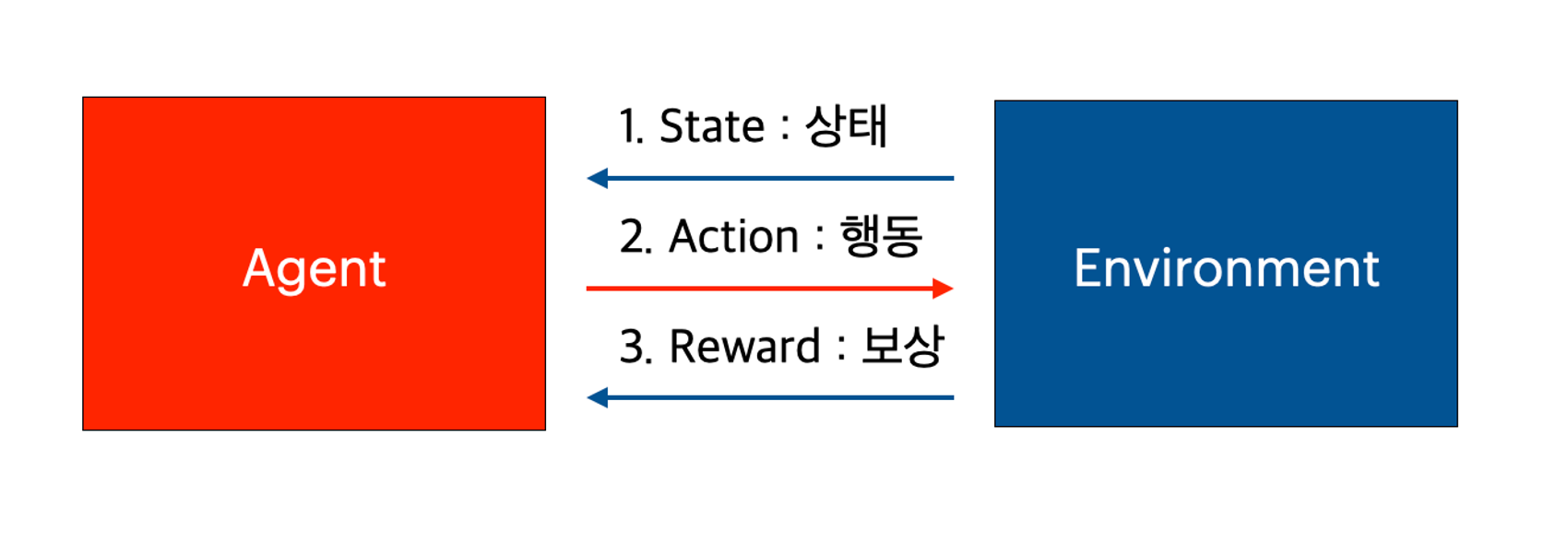
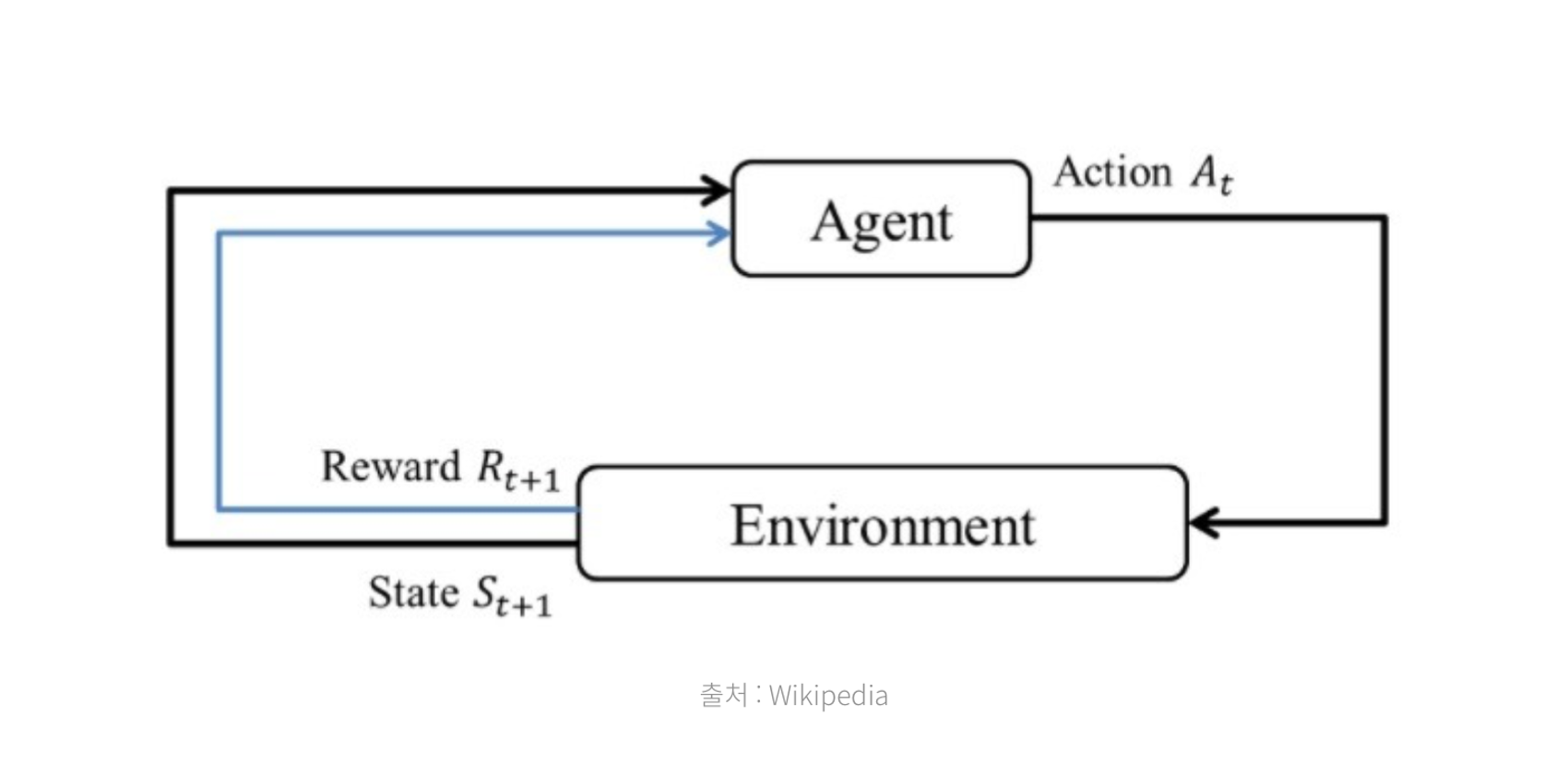
강화학습에서 학습은 **에이전트와 환경의 상호작용을 통해 이뤄진다.
- 먼저 환경이 현재 에이전트의 상태를 에이전트한테 제공한다.
- 에이전트는 받은 상태에서 어떤 행동을 할 것인지 선택하고, 행동한다.
- 환경은 에이전트의 행동을 받고, 그에 따른 보상과 행동에 따라 변한 상태를 에이전트에게 반환한다.
- 이때 에이전트는 행동에 따라 변화된 여러 상태를 탐험하는 과정을 반복하며 어떤 행동을 해야 좋은 결과를 얻는지를 학습한다.
순차적 행동 결정 문제
- 순차적으로 행동을 결정하는 문제를 정의할 때 사용하는 방법이 MDP(Markov Decision Process)이다. MDP는 순차적 행동 결정 문제를 수학적으로 정의해서 에이전트가 순차적 행동 결정 문제에 접근할 수 있게 한다.
강화학습의 구성요소
-
state(상태)
상태는 환경이 에이전트에게 제공하는 현재 상황 정보다. 에이전트는 상태를 관찰하고, 이를 바탕으로 행동을 선택하게 된다. 상태는 환경에서 에이전트가 취할 수 있는 모든 정보를 포함하며, 에이전트가 처한 상황을 완전히 설명한다.
-
action(행동)
행동은 에이전트가 주어진 상태에서 취할 수 있는 선택을 의미한다.
일반적으로 모든 상태에서 같은 행동 집합이 존재한다.
- Action space
-
discrete : 가능한 행동의 수가 유한하고 명확하게 구분되는 경우
ex) (앞, 뒤, 좌, 우)
-
continuous : 행동이 연속적인 값의 범위 내에서 이루어지는 경우
ex) 로봇 팔의 회전 각도
-
range : 이산적 공간과 연속적 공간의 특징을 모두 포함하는 개념으로, 행동이 특정 구간 내의 값을 가질 수 있는 경우
ex) 로봇 팔의 각도를 -30도에서 30도 사이로 제한
-
- Action space
-
policy(정책)
정책은 모든 상태에서 에이전트가 어떤 행동을 해야하는지 알려주는 지표다. 정책은 가능 행동이 각각 선택될 확률을 지정하고, 그 확률을 행동 선택의 지표로 사용한다.
단순할 경우, 정책은 모든 상태에 모든 행동의 확률을 적어둔 표로 표현할 수 있다. 하지만 일반적인 상황에서 이는 엄청난 양의 계산 비용을 필요로 하기에 비효율적이라는 단점이 있다.
- 결정적 정책 : 특정 상태에서 항상 동일한 행동을 선택한다.
- 확률적 정책 : 특정 상태에서 여러 행동을 확률적으로 선택한다.
-
reward(보상)
보상이란 에이전트 행동에 대해 환경이 전달해주는 숫자값이다. 보상은 행동을 했을 때 즉각적으로 그 행동이 좋은지, 나쁜지 평가해주는 지표가 된다. 따라서 보상은 특정 상태에서 특정 행동이 좋은지 나쁜지를 알 수 있고, 간접적으로 규칙을 학습하는 지표가 된다.
-
value(가치)
가치란 특정 상태의 시작부터 일정 시간 동안 에이전트가 기대할 수 있는 보상의 총량이다. 따라서 가치는 장기적인 관점에서 상태를 표현할 수 있고, 이는 행동 보상의 합을 최대로 만들고자하는 강화학습의 학습 목표와 밀접하다. 따라서 일반적으로 에이전트는 보상 대신, 가치를 기준으로 행동을 결정한다.
- Gamma(할인율) : 에이전트가 미래에 얻을 보상을 현재 시점으로 얼마나 할인해서 고려할지를 결정 $(0≤\gamma≤1)$
- $\gamma$=1 : 미래의 보상을 현재와 동일하게 고려한다.
- $\gamma$=0 : 미래 보상을 전혀 고려하지 않고, 즉각적인 보상만을 중요하게 여긴다.
- 0<$\gamma$<1 : 미래 보상은 현재보다 덜 중요하게 고려된다.
- Gamma(할인율) : 에이전트가 미래에 얻을 보상을 현재 시점으로 얼마나 할인해서 고려할지를 결정 $(0≤\gamma≤1)$
-
model(주변 환경에 대한 모델)
환경 모델은 환경의 변화를 모사해, 환경이 어떻게 변할 지를 추정할 수 있게 해준다. 환경 모델은 현재 상태와 행동으로부터 다음 상태와 보상을 예측한다. 이런 모델을 사용하는 경우를 모델 기반 방법이라 한다. 반대로, 모델 없이 전적으로 시행착오를 통해 학습하는 경우는 model-free 방법이라 한다.
- Model-based : 에이전트가 환경을 완전히 알거나 예측할 수 있는 경우에 사용된다
- Model-free : 에이전트가 환경 모델 없이 직접 상호작용을 통해 학습한다.
환경과 에이전트 : 구성 요소를 바탕으로
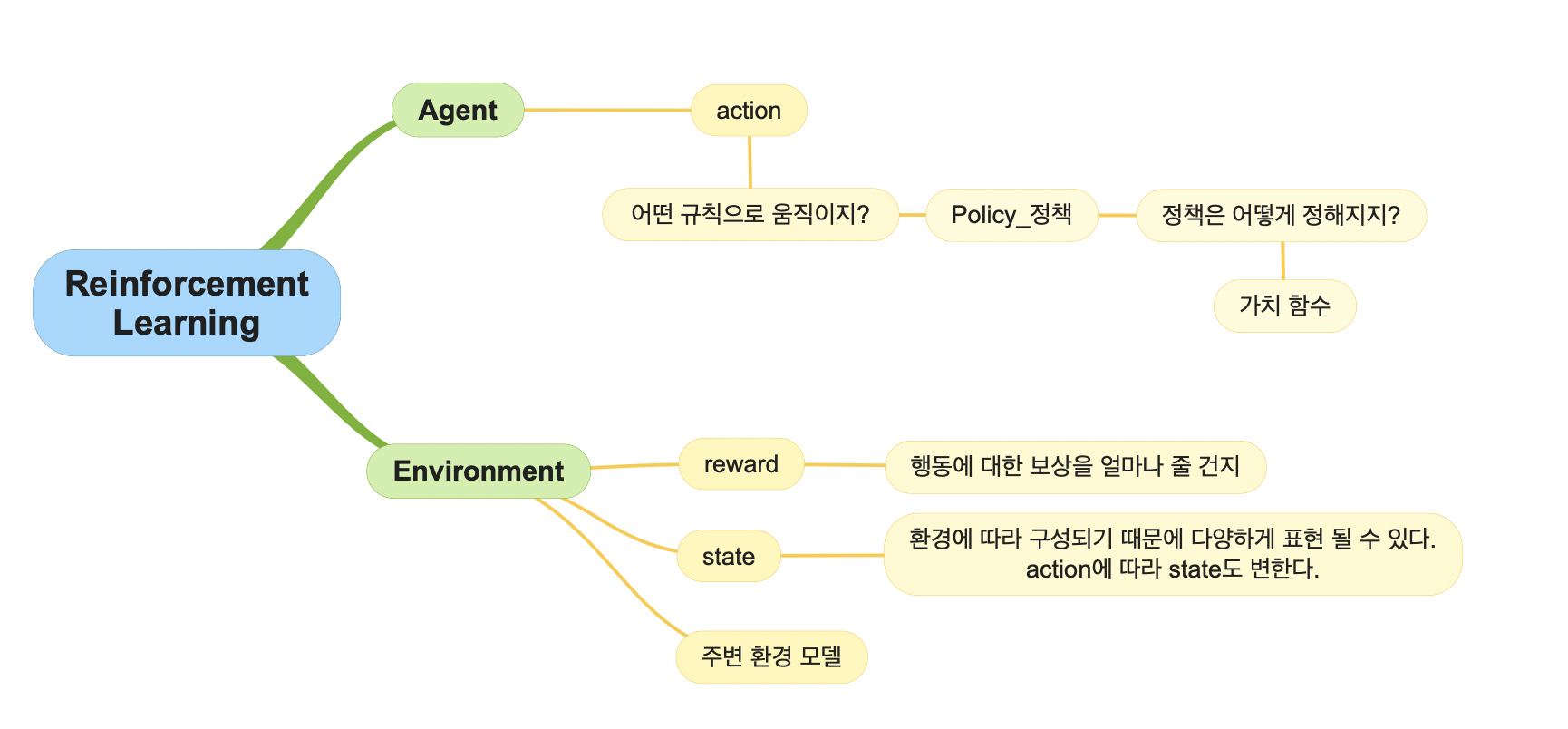
에이전트는 행동, 정책을 담당하고 환경은 보상, 상태, 환경 모델을 담당한다.
강화학습 예시
EX1) 바둑
- Objective (목표) : 에이전트의 최종 목표는 바둑 게임에서 승리하는 것이다.
- State (상태) : 흑돌, 백돌, 빈 상태
- Action Space (행동 집합) : 다음 바둑돌을 어디에 놓을지 결정하는 것이다. 바둑판의 크기가 19x19일 때, 0~360까지 총 361개의 칸 중 선택 가능하다.
- Reward (보상) : 게임이 끝났을 때 이기면 1점을 얻고, 그렇지 않으면 0점을 얻는다.
Ex2) 지뢰찾기
- Objective (목표) : 지뢰를 밟지 않고 모든 안전한 칸을 여는 것이다.
- State (상태) : 주변부 지뢰의 개수를 센 타일의 수(0-8), 아직 까지지 않은 타일을 -1, 지뢰를 -2로 표현
- Action (행동) : 9x9 지뢰찾기에서 0~80까지 총 81개의 칸 중 선택 가능하다.
-
Reward (보상) : 에이전트가 안전한 칸을 열었을 때, +1의 보상을 얻는다. 에이전트가 지뢰를 클릭했을 때, -1 보상을 받는다. 이미 누른 타일을 또 누른 경우도 고려한다.
Reward Description & Purpose Weight Done Win 지뢰가 아닌 모든 타일을 깐 경우 1 True Lose 깐 타일이 지뢰인 경우 -1 True Progress 주변부에 까진 타일이 있고, 지뢰가 아닌 타일을 깐 경우 0.3 False Guess 주변부가 까져 있지 않지만, 지뢰가 아닌 타일을 깐 경우 -0.3 ~ 0.3 False No Progress 이미 누른 타일을 또 누른 경우 -0.5 / -1 T/F
강화학습 정책
Reward와 Value의 차이
보상은 에이전트가 특정 행동을 취한 직후에 환경으로부터 받는 즉각적인 피드백이다. 보상은 한 번의 행동에 대한 결과로 주어지며, 해당 행동 직후에 바로 받는 값이다. 즉각적이며, 현재 상태에서의 행동에 대한 단기적인 결과이다.
가치는 특정 상태(State) 또는 상태-행동(State-Action) 쌍에서 장기적으로 기대할 수 있는 보상의 총합을 의미한다. 즉, 가치는 현재 상태에서 에이전트가 앞으로 받을 보상을 모두 합산한 기대값이다.
가치함수
상태 가치 함수 V(s)는 **상태 s에서 시작했을 때, 에이전트가 정책 $\pi$를 따랐을 때 앞으로 받을 수 있는 기대 보상의 총합을 나타낸다.
상태-행동 가치 함수 Q(s,a)는 상태 s에서 특정 행동 a를 했을 때, 그 후 정책 $\pi$를 따랐을 때 에이전트가 받을 기대 보상의 총합을 나타낸다.
참 가치함수는 현재 에이전트가 따르고 있는 정책에 따른 실제 기대 보상을 나타낸다. 정책 평가(Policy Evaluation) 단계에서 에이전트가 현재 정책에 따라 얻을 수 있는 보상의 기대값을 계산하는 데 사용된다.
최적 가치함수는 에이전트가 최적의 정책(Optimal Policy)을 따랐을 때 얻을 수 있는 최고의 기대 보상을 나타내는 가치 함수이다. 정책 개선(Policy Improvement) 과정에서 목표로 삼는 지표입니다. 에이전트는 최적 가치함수에 도달할 수 있도록 현재 정책을 개선해 나가며, 최적 정책을 학습하게 된다.
최적정책(Optimal Policy)
최적 정책은 강화학습에서 에이전트가 각 상태에서 장기적으로 기대할 수 있는 보상을 최대화할 수 있는 정책을 의미한다.
최적 상태 가치 함수 $V^(s)$는 최적 정책 $\pi^$를 따랐을 때 각 상태 s에서 받을 수 있는 보상의 기대값이다.
*최적 상태-행동 가치 함수 $Q^(s, a)$는 **최적 정책 $\pi^*$를 따랐을 때, 상태 s에서 행동 a를 선택했을 때의 기대 보상이다.
탐험과 활용
탐험(Exploration)은 에이전트가 새로운 상태와 새로운 행동을 시도하여 환경에 대한 더 많은 정보를 얻는 과정이다. 에이전트가 아직 잘 모르는 상태나 행동을 시도하여, 장기적으로 더 나은 보상을 얻을 수 있는 기회를 탐색하는 역할을 한다.
활용(Exploitation)은 에이전트가 이미 알고 있는 정보를 바탕으로, 현재 상태에서 가장 높은 보상을 줄 것으로 예상되는 행동을 선택하는 과정입니다. 이미 수집된 정보에 의존하여, 현재 시점에서 최선의 행동을 취하려는 전략이다.
탐욕적 정책
탐욕적 정책(Greedy Policy)는 강화학습에서 현재 상태에서 가장 즉각적인 보상을 최대화할 수 있는 행동을 선택하는 정책을 의미한다. 즉, 에이전트는 주어진 상태에서 그 순간 가장 큰 보상을 기대할 수 있는 행동을 선택한다. 탐욕적 정책은 탐험을 전혀 하지 않으므로, 새로운 행동을 시도하거나 미지의 상태에서 더 나은 보상을 발견할 가능성을 놓친다.
탐욕적 정책의 단점을 보완한 ϵ-탐욕 정책은 탐험과 활용의 균형을 맞춰, 에이전트가 단기적인 보상과 장기적인 최적화를 모두 고려할 수 있도록 돕는다. 초기에는 탐험을 많이 하고, 시간이 지남에 따라 탐험의 비율 ϵ을 점점 줄여간다.
출처
- 파이썬과 케라스로 배우는 강화학습
- https://recondite-lungfish-fd3.notion.site/a50bd36fb7e545a28644c652222e611b#8e27622b245949aea36700a4eb79ed0f