[강화시스터즈 1기] 다이나믹 프로그래밍
다이나믹 프로그래밍에 대하여,
- 다이나믹 프로그래밍이란?
다이나믹 프로그래밍은 1940년대 벨만이 MDP 문제를 해결하기 위해 고안한 방법론이다. 다이나믹 프로그래밍은 하나의 큰 문제를 여러 개의 작은 문제로 나눈 후, 단계적으로 문제를 해결한다. 작은 문제의 결과물을 저장하고, 저장한 값을 큰 문제를 해결할 때 꺼내와 사용하는 것이다.
예를 들어, 다이나믹 프로그래밍을 이용하여 피보나치 수열을 계산할 수 있다. 피보나치 수열은 $t$ time step에서 $t-1, t-2$ 스텝의 값을 더한 값을 갖는다. (단 $F_1=F_2=1$) 특정 시점 $F_t$은 각 $F$의 값이 1이 될 때까지 $F_{t-1}+F_{t-2}$로 문제를 쪼개며 재귀적인 형태로 해결할 수 있다.
def fibo(n):
if n == 1 or n == 2:
return 1
else:
return fibo(n-1) + fibo(n-2)
- 다이나믹 프로그래밍의 한계 및 의의
다이나믹 프로그래밍은 완벽한 모델, 엄청난 양의 계산량이 필요해 현재 강화학습 방법론으론 이용하지 않는다. 하지만 현재 사용 되어지는 강화학습 방법론들은 다이나믹 프로그래밍을 기반으로 발전했다. 따라서 다이나믹 프로그래밍을 학습에 사용하지 않더라도 그 이론을 이해하는 것은 매우 중요하다.
- 다이나믹 프로그래밍의 방법론
다이나믹 프로그래밍을 이용해 순차적 행동 결정 문제를 푸는 방법론에는 정책 이터레이션과 가치 이터레이션이 있다.
정책 이터레이션(정책 반복)
정책 이터레이션은 기존의 정책에 따른 가치 함수를 계산하고, 정책을 발전시키는 과정을 반복하며 최적 함수를 구한다. 이때 가치 함수를 정책에 따라 계산하는 부분을 정책 평가라 하고, 구한 가치함수를 바탕으로 정책을 개선하는 것을 정책 발전이라 한다.
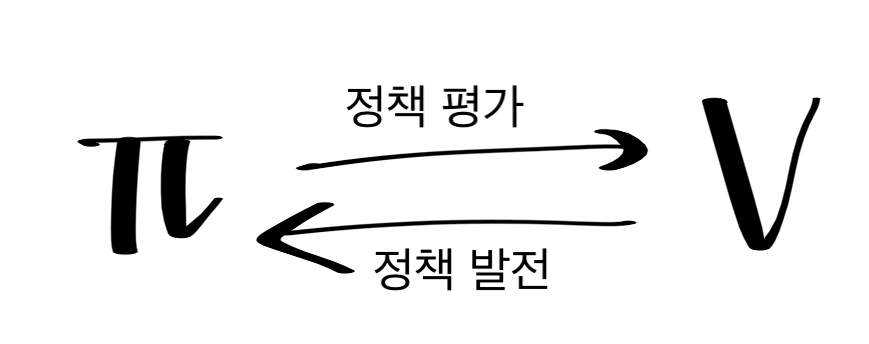
$\pi_0 →^E V_{\pi_0} →^I \pi_0 →^E V_{\pi_0} →^I … → \pi_* → V_{\pi_*}$ E : 정책 평가 I : 정책 발전
정책 평가
정책 평가는 다이나믹 프로그래밍을 사용해 벨만 기대 방정식을 계산한다.
- 벨만 기대 방정식 : 특정 정책을 따라갔을 때 이어지는 두 상태 간의 관계 표현
- 현 상태를 갈 수 있는 주변 모든 상태들의 가치함수와 보상으로 표현함
$V_{k+1} = \sum_{a \in A} \pi(a|s) \sum_ {s’,r} P(s’,r|a,s)[r(s,a) + \gamma V_{k}(s’)]$
정책 평가는 반복을 통해 벨만 방정식의 등호가 성립하는 $V_k=V_\pi$를 찾는다. 이론적으로 $k→\infin$일 때, $V_k=V_\pi$이 성립한다. 정책 평가는 $V_k=V_\pi$인 값을 찾기 위해, 모든 상태를 돌아다니며 근삿값을 구해 상태 $s$의 가치함수를 갱신하는 과정을 거친다. 상태 s 이후에 나타나는 상태들의 이전 가치와 보상의 기댓값을 업데이트하기 때문에 기댓값 갱신이라 표현하기도 한다.
이런 반복 정책 평가를 구현하기 위해서는 이전 가치를 담는 배열과 갱신된 현재 가치를 담는 배열이 필요하다. 하지만 정책 평가의 핵심은 값의 업데이트를 통한 수렴이기에, 굳이 이전의 데이터를 저장할 필요가 없다. 따라서 이 알고리즘은 두 배열을 구분하지 않고, 하나의 배열만을 이용한다. 하나의 배열을 사용해 각 상태의 값을 갱신하는 방법은 두 개를 사용하는 방법보다 더 빠르게 수렴하는 장점 또한 존재한다.
아래는 각 상태의 가치 함수를 저장하는 하나의 배열을 사용해 정책 평가를 구현하는 의사 코드다.
loop:
Δ ← 0
for s in S:
v ← V(s)
V(s) ← 벨만 기대 방정식
Δ ← max(Δ, |v - V(s)|)
loop until Δ < 0
- 모든 상태에 대해 벨만 기대 방정식을 통해 가치 함수의 값을 업데이트 한다.
- for 문을 통해서 전체 상태를 훑는 것을 나타낸다. 이 과정은 가치 함수가 최적 가치 함수일 때 중단된다.
- $Δ$는 이전 상태의 가치 함수 값과 갱신된 가치 함수 값의 오차를 담는다. 결과적으로 $Δ$는 반복하는 하나의 과정 중 최대 오차를 담게 된다. 이를 통해 $V_k=V_\pi$ 상태가 되면 이전 상태의 가치 함수 값과 갱신된 가치 함수 값의 간격이 0에 수렴한다는 성질을 이용할 수 있다. 만약 전체 상태에서 이 값의 최대값이 0으로 수렴한다면, 이 가치 함수는 현 정책에 대한 최적 가치 함수라고 해석할 수 있다.
정책 발전/향상
정책 발전은 정책 평가 이후에 이루어지며, 현재 정책과 가치함수 계산을 통해 새로 구해진 정책을 저울질한다. 현재 정책 $\pi$보다 $\pi’$이 더 좋다고 나왔을 때, 어떤 것이 정말 좋은 방식인지를 선택한다. 이는 현재 상태 $s$에서 $\pi ‘(s)$인 $a$를 선택한 이후에 현재 정책 $\pi$을 따르는 값, $q_{\pi}(s,a)$와 $v_{\pi}(s)$의 비교해 찾아낼 수 있다.
$q_{\pi}(s,a) ≥ v_{\pi}(s)$ → 현재 정책 $\pi$에서 $\pi’$로 업데이트 한다.
만약 $q_{\pi}(s,a)$ 이 $v_{\pi}(s)$보다 크다면 항상 현재 정책을 따르는 것보다 상태 $s$에서 행동 $a$를 선택하는 것이 더 좋다고 해석할 수 있다. 따라서 정책 $\pi ‘$이 모든 상태로부터 도출하는 기댓값이 정책 $\pi$가 도출하는 것보다 크거나 같아야 한다.
큐함수와 상태 가치 함수가 혼재 되어 있는 식은 아래의 유도 과정을 통해 상태 가치 함수 간의 식으로 정리된다.
$q_{\pi}(s,a) ≥ v_{\pi}(s)$ → $v_{\pi ‘}(s) ≥ v_{\pi}(s)$
- 유도 과정
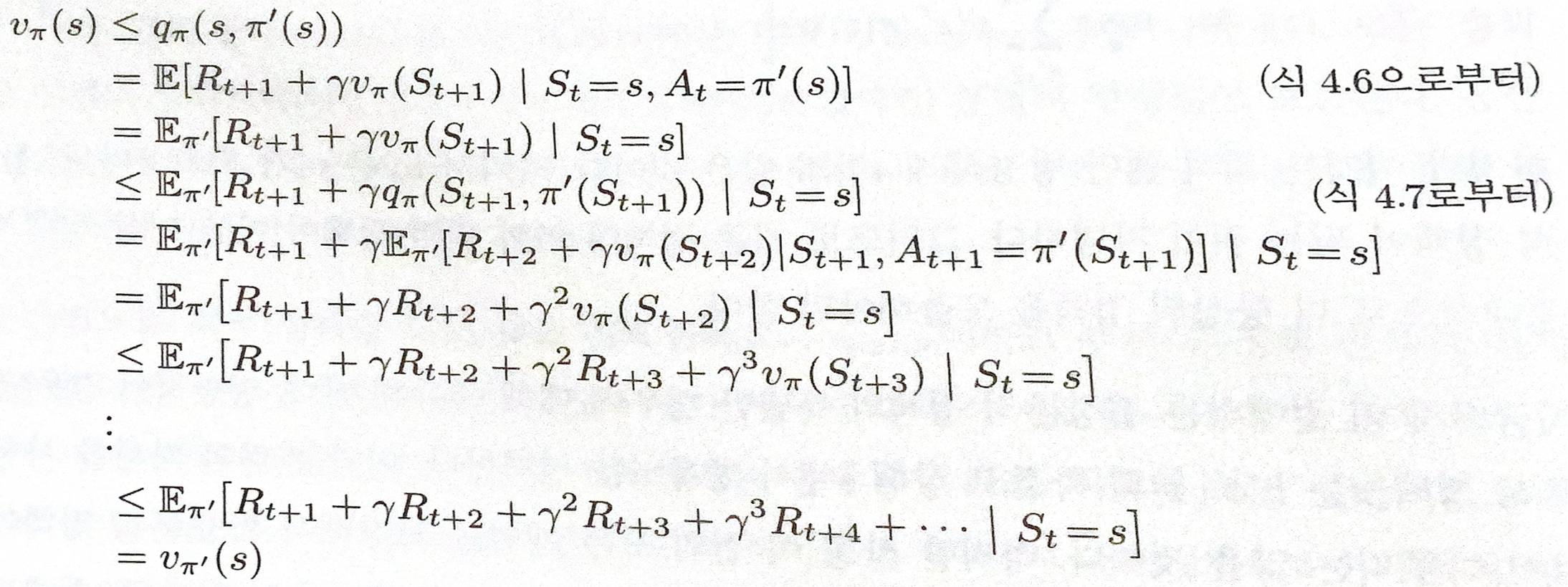
정책 이터레이션의 한계
정책 이터레이션은 정책 평가의 종료 이후에만 정책 발전이 가능하다는 것과 반복 주기마다 매번 정책 평가를 진행한다는 단점이 있다. 정책 평가는 많은 양의 반복 행동을 수반해 연산량이 많다. 따라서 이 과정을 매 주기마다 진행하는 것은 효과적이지 않다. 또한 정책 평가 과정의 복잡성은 의미없는 연산의 반복 수행을 발생시킬 수 있다.
가치 이터레이션(가치 반복)
가치 이터레이션은 정책 이터레이션의 중단된 정책 평가 단계와 정책 발전 단계를 합한 알고리즘이다.
정책 이터레이션은 매 주기마다 $V_k →V_\pi$로의 수렴이 목적인 정책 평가를 시행한다. 또한 매 정책마다 정책 평가를 끝까지 진행하지 않아도 된다. 정책 이터레이션 과정을 무수히 반복하다보면 값의 수렴성이 보장되기 때문이다. 이는 중단된 정책 평가에서도 수렴성을 보장하기 때문에 의미가 있다.
가치 이터레이션은 정책 평가와 정책 발전을 합친 벨만 최적 방정식을 계산한다.
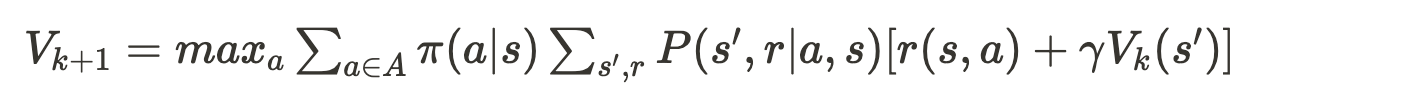
아래는 벨만 최적 방정식을 이용해 가치 이터레이션을 수행하는 의사 결정 코드다. 벨만 기대 방정식이 최적 방정식으로 바뀐 것을 제외하면 정책 이터레이션의 정책 평가와 동일한 구조를 갖고 있다.
loop:
Δ ← 0
for s in S:
v ← V(s)
V(s) ← 벨만 최적 방정식
Δ ← max(Δ, |v - V(s)|)
loop until Δ < 0
가치 이터레이션에서 현재 상태의 가치는 가능 행동들의 가치 중 최댓값이다.
가치 이터레이션은 정책 이터레이션과 달리 별도의 정책 테이블을 갖지 않으며, 가치 테이블만으로 다음 행동을 구한다. 저장된 가치 테이블을 이용해 행동 별 가치를 구하고, 그 중 가장 가치가 큰 행동을 이행한다.
비동기 동적 프로그래밍
- 가치 이터레이션과 정책 이터레이션의 의사 결정 코드
정책 이터레이션
loop:
Δ ← 0
for s in S:
v ← V(s)
V(s) ← 벨만 기대 방정식
Δ ← max(Δ, |v - V(s)|)
loop until Δ < 0
가치 이터레이션
loop:
Δ ← 0
for s in S:
v ← V(s)
V(s) ← 벨만 최적 방정식
Δ ← max(Δ, |v - V(s)|)
loop until Δ < 0
가치 이터레이션과 정책 이터레이션은 전체 상태 집합을 이용한다. 이 방법론은 상태 집합이 매우 크다면 계산량이 폭등한다는 단점이 있다. 비동기 동적 프로그래밍은 상태 집합에 대해 체계적인 일괄 계산을 수행하지 않는 개별 반복 DP 알고리즘으로써 이 문제를 해결한다.
이 알고리즘은 상태 갱신의 순서가 중요하지 않다. 따라서 다른 상태의 가치를 이용할 수 있는 상황이라면, 즉시 해당 상태를 업데이트하는 것이 가능하다. 다시 말해, 어떤 상태가 한 번 갱신될 동안 다른 상태가 여러 번 갱신되는 것이 가능하다. 이는 전체 상태 집합에 대한 갱신이 이뤄져야 같은 상태에서 갱신이 가능한 가치, 정책 이터레이션과의 차별점이다. 물론 정확하게 수렴이 되기 위해서는 모든 상태의 가치의 갱신이 필요하다. 다만, 부분적인 갱신이 가능하다는 점에서 앞선 DP에 비해 효율적이다.
비일괄 계산 방법은 좋은 결과를 확실하게 보장하진 못한다. 그럼에도 이 방법은 정책 향상을 위해 무의미한 일괄 계산만을 붙들고 있지 않아도 되며,학습의 유연성을 보장해주고, 상태 간의 효율적인 전파를 돕기에 의미가 있다.
GPI
정책 이터레이션은 정책 평가와 정책 발전으로 구성되어 있다. 정책 평가를 통해 현 정책을 따르는 가치 함수를 구할 수 있고, 정책 발전을 통해 현재 가치 함수에 대한 탐욕적 정책을 얻을 수 있다. 정책 평가와 발전은 서로 상호작용하며 하나가 종결된 이후에 하나가 시작되는 맞물린 구조다. GPI는 이 맞물린 과정을 정의한다. GPI의 구조는 거의 대부분의 강화학습에서 사용된다. 이는 거의 대부분의 강화 학습에는 식별 가능한 정책과 가치함수가 사용한다는 것으로 해석할 수 있다.
정책과 가치함수는 서로 상호작용하며 값을 변화시킨다. 만약 정책과 가치함수가 최적화되면, 서로를 변화시키지 않고 안정된다. 가치 함수는 현재 정책만을 따를 때 안정화될 수 있고, 정책은 계산된 가치 함수에 대해 탐욕적일 때만 안정화될 수 있다. 따라서 가치 함수에 대한 탐욕적인 최적 정책을 찾을 수 있을 때만 두 과정이 안정된다.
GPI에서 평가와 발전은 경쟁적인 동시에 협력적이다. 평가와 발전은 최적의 상태가 아닌 이상 서로를 변화시킨다. 정책이 가치 함수에 대해 탐욕적으로 구해지면 가치 함수는 변경된 정책에 대해 부정확하며, 가치 함수가 현재 정책만을 따르게 만들면 그 값은 더 이상 탐욕적이지 않게 된다. 그러나 상호 경쟁적인 이 두 과정의 상호작용을 통해 최적 가치 함수, 최적 정책을 구할 수 있다. 따라서 GPI에서의 평가와 발전은 서로 다른 방향으로 움직이는 것 같지만, 결국 최적화라는 공통해를 찾기 위해 움직인다.