[강화시스터즈 1기] CNN 개념 정리
CNN의 등장 배경
- 전연결 신경망 (Fully Connected Neural Network)이 받을 수 있는 input data는 1차원 배열으로 한정된다.
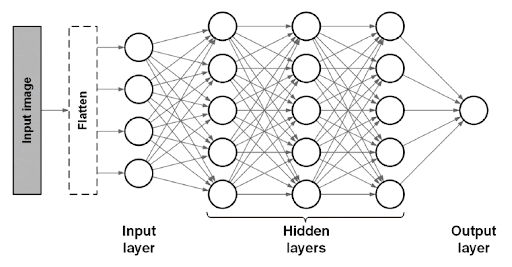
- 하지만 이미지 데이터는 (컬러 이미지의 경우) 가로x세로xRGB채널의 shape을 가진 3차원 배열이고, 배치 모드에 사용되는 여러 장의 이미지는 심지어 배치 크기에 대한 차원까지 추가되어 4차원 배열 형태가 되어버린다.
-
이러한 이미지 데이터를 전연결 신경망을 이용하여 학습시키고 싶다면 3차원을 1차원으로 평면화(flatten)시켜야 하고, 이 과정에서 공간 정보가 손실된다.
➡️ 이미지 공간 정보 유실로 인한 정보 부족
- 전연결 신경망은 이름 그대로 각 층의 모든 노드가 다음 층의 모든 노드와 연결되기 때문에 매우 많은 파라미터가 필요하다. 네트워크 크기나 input 데이터 크기가 증가할수록 계산 시 코스트가 매우 높아지고 overfitting되기 쉬워진다.
➡️ 인공 신경망이 특징을 추출하고 학습하는 것이 비효율적이며 정확도를 높이는 데에 한계가 있다.
📌 그래서 이미지의 공간 정보를 유지한 상태로 학습이 가능한 모델의 필요성이 대두되었고, CNN(합성곱 신경망, Convolutional Neural Network)가 탄생했다. CNN은 각 레이어의 입출력 데이터의 형상을 유지하고, 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식할 수 있다는 장점이 있다.
CNN의 기본 구조
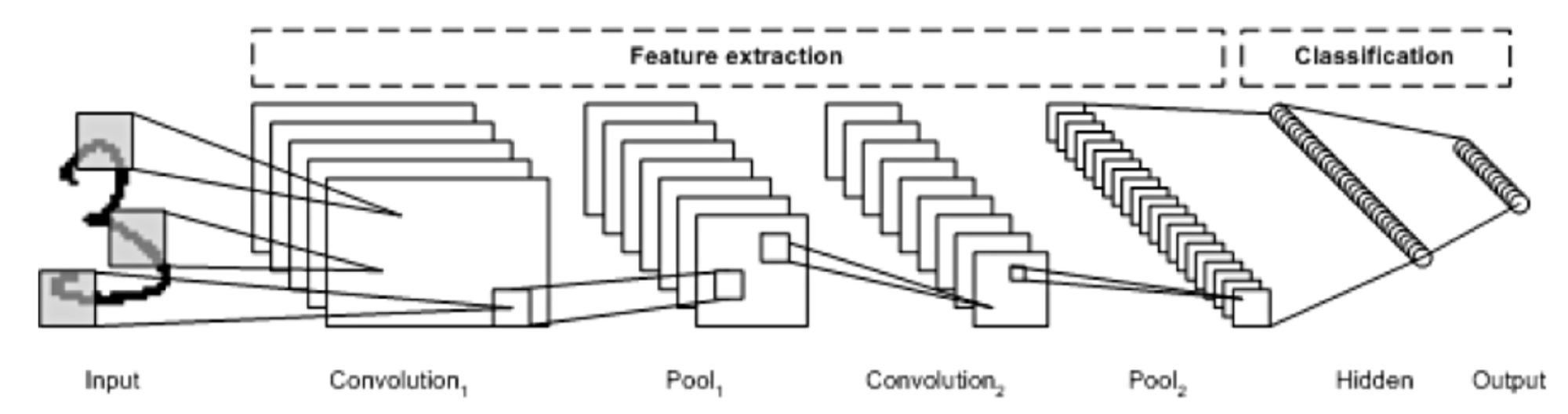
- CNN은 위와 같이 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있다.
- 특징 추출 영역은 Convolution layer와 Pooling layer를 여러 층 쌓는 형태로 구성된다. 이 때 Pooling layer는 선택적인 층이다.
- CNN 마지막 부분에는 이미지 classification을 위한 fully connected layer가 추가된다. 그리고 특징 추출 부분과 분류 부분 사이에 이미지 형태의 데이터를 배열 형태로 만드는 flatten 레이어가 있다.
CNN 주요 용어들
합성곱 Convolution
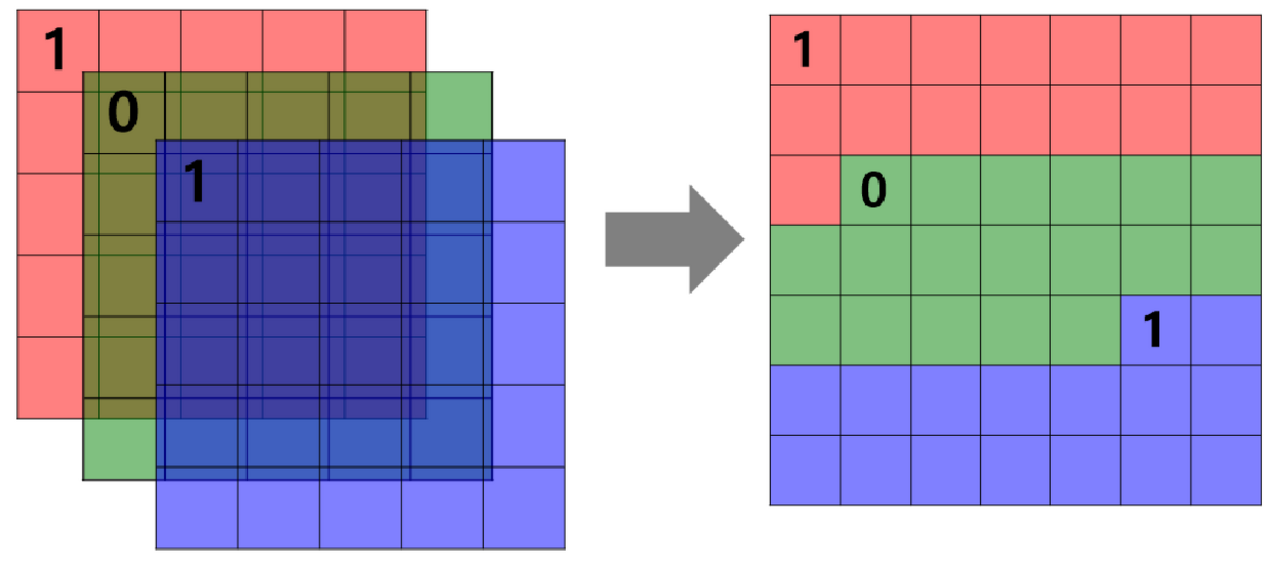
- CNN은 이미지 특징 추출을 위해 필터가 input 데이터를 순회하며 합성곱을 계산하고, 그 결과를 이용해 feature map을 만든다.
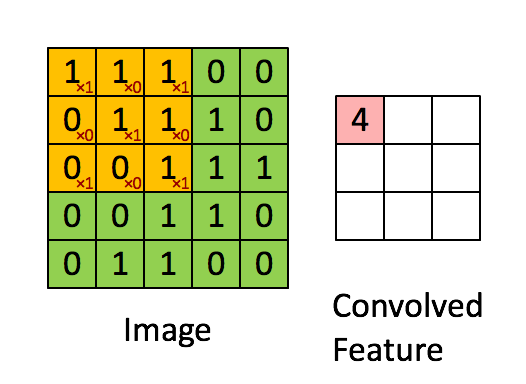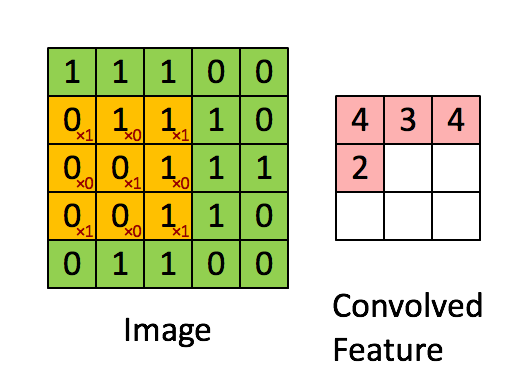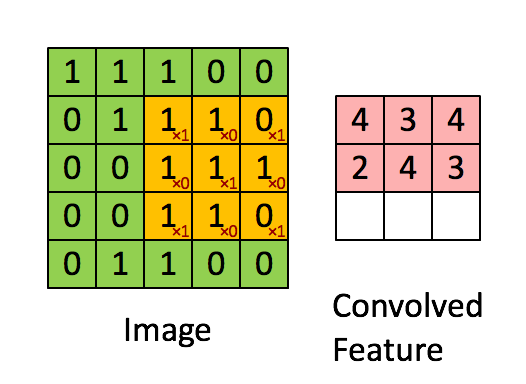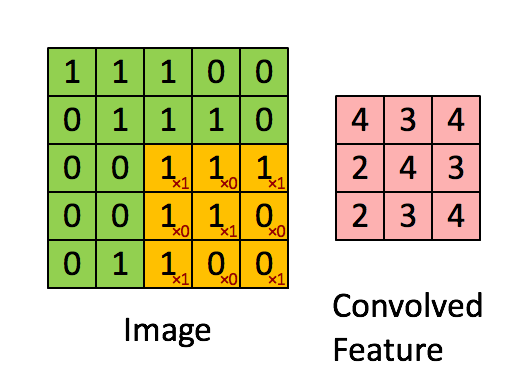
-
Stride는 필터가 순회하는 간격을 말한다.
e.g) stride=2 인 경우
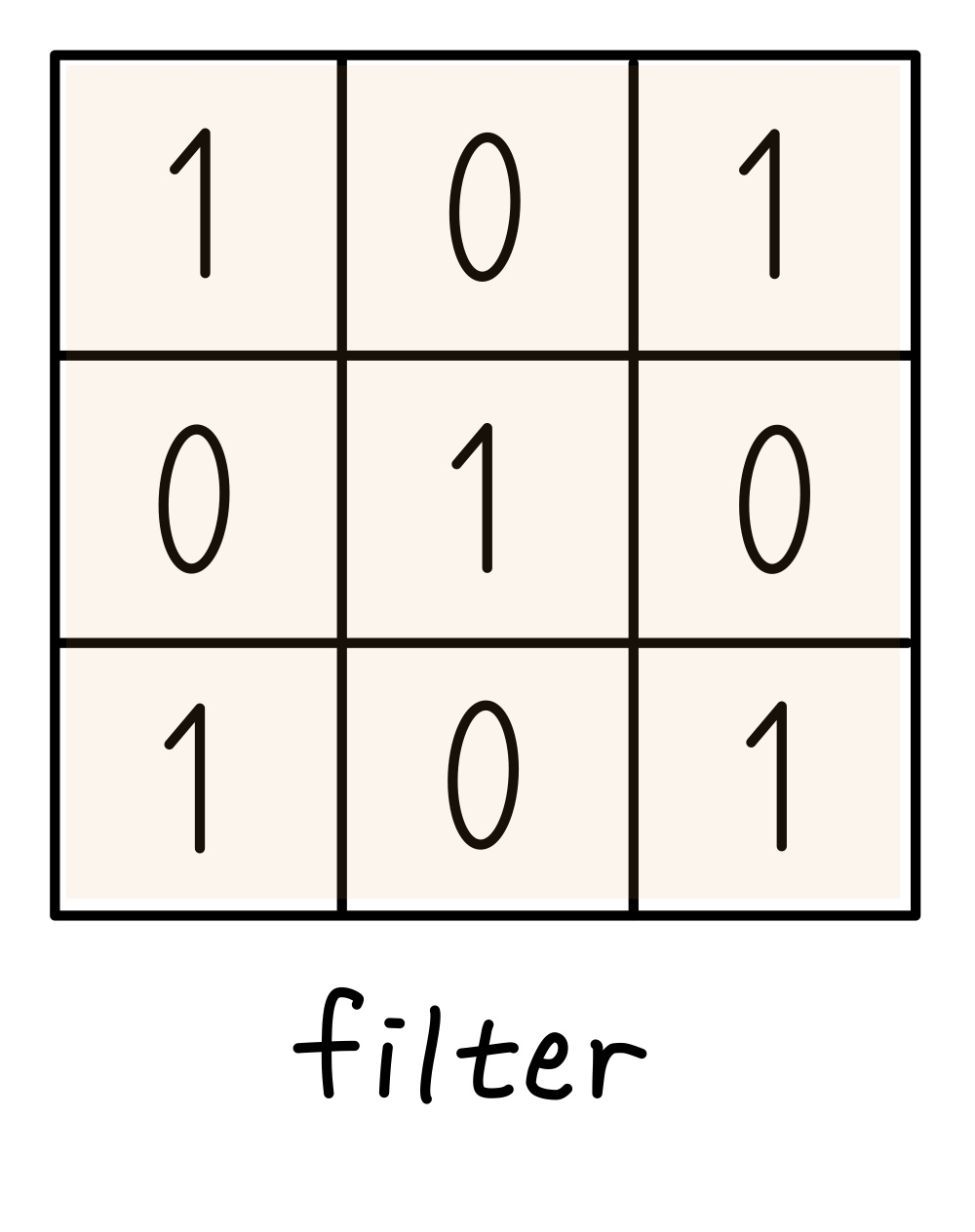

⬇️
e.g.) 채널이 3개인 경우
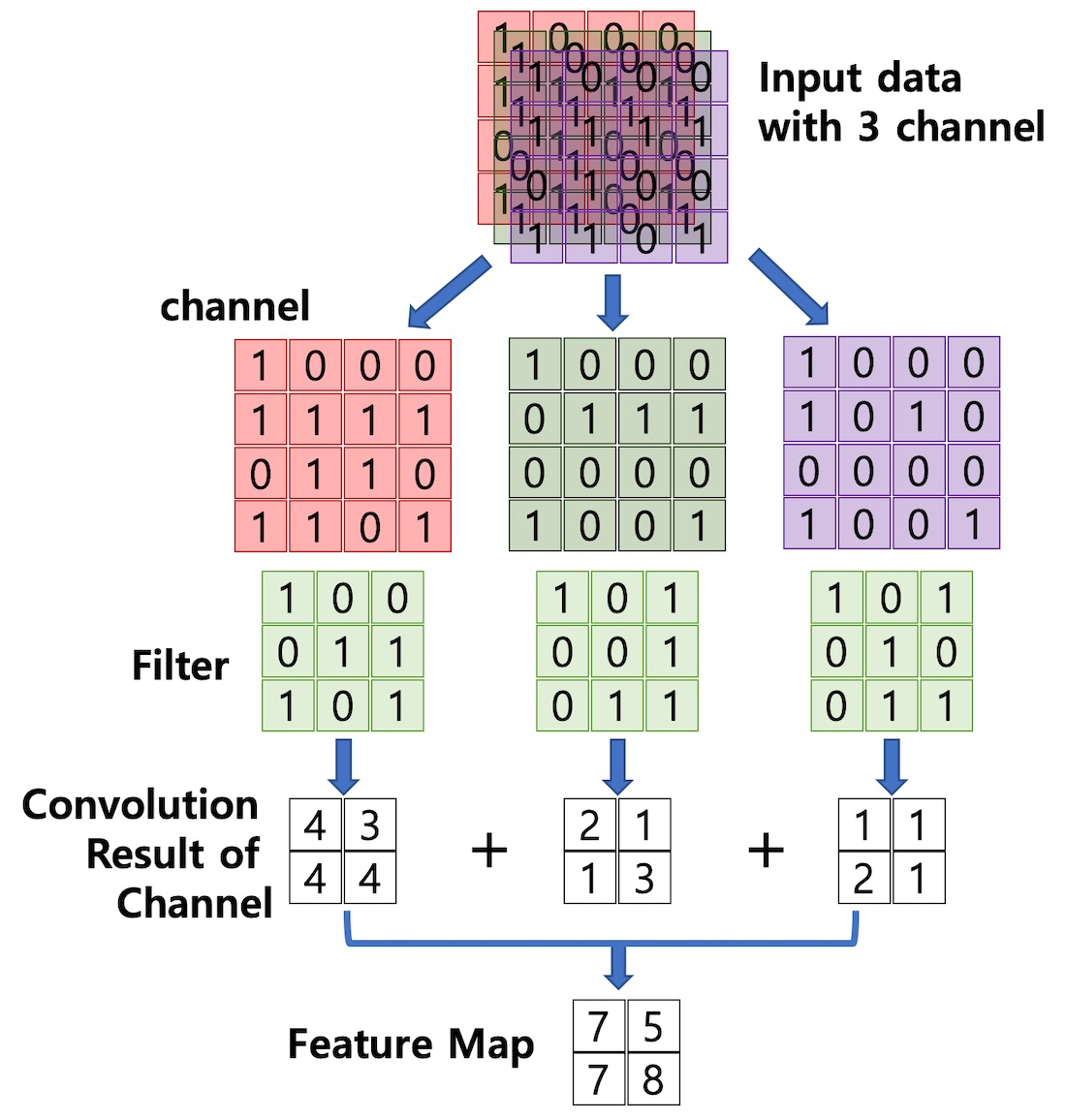
- 합성곱 연산을 통해 만든 행렬들을 feature map이라고 하며, 여기에 활성화 함수를 적용한 최종 출력 결과는 activation map이라고 한다.
- Convolution layer에 들어오는 입력 데이터에는 한 개 이상의 필터가 적용되고, 필터의 개수는 feature map의 채널 개수가 된다.
필터 Filter
- 이미지의 특징을 찾아내기 위한 공용 파라미터이다.
- = Kernel
- 일반적으로 정방행렬(NxN)으로 정의된다.
- CNN에서 학습의 대상은 필터 파라미터이다.
- Convolution 과정에서 패턴 같은 특징을 잡는 다양한 필터들이 사용되고, 이러한 필터들을 통해 만들어진 feature map의 채널이 쌓일수록 더 global한(전체적인) 이미지를 인식할 수 있게 된다.
패딩 Padding
- Filter와 Stride의 작용으로 Convolution layer의 Feature Map 크기는 입력 데이터보다 작아진다. 이렇게 사이즈가 작아지는 것을 방지하는 방법이 패딩이다.
- 패딩은 입력 데이터의 외곽에 지정된 픽셀만큼 특정 값으로 채워 넣는 것을 의미한다.
- 패딩의 종류
- zero padding
- reflect padding
- symmetric padding
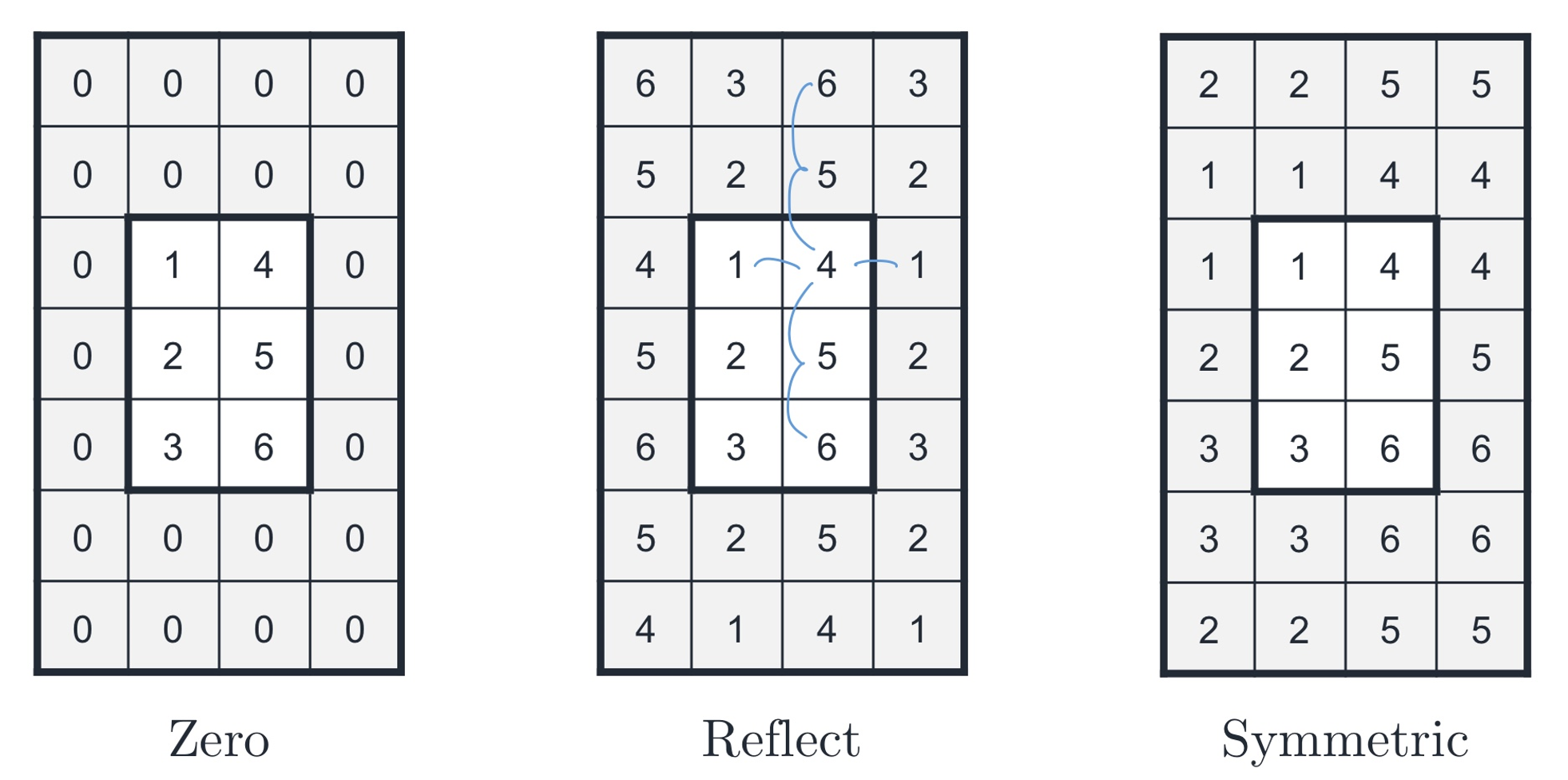
-
보통 zero padding을 사용한다.
— 출력 데이터의 사이즈를 입력 데이터와 동일하도록 조절하는 기능 외에도 외곽을 둘러싼 0 값들로 인해 신경망이 이미지의 외곽을 인식하는 학습 효과도 있기 때문이다.
- 이미지 사이즈 키우는 기능 외에도 이미지 가장자리 픽셀들은 필터가 순회하는 빈도가 적음 → 패딩 통해 주변을 늘려줌으로써 기존 이미지 가장자리도 필터가 좀 더 중요하게 인식할 수 있도록 한다.
Pooling
- Pooling layer는 convolution layer의 출력 데이터를 입력으로 받는다.
- 그리고 출력 데이터의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용된다.
- 파라미터가 없다.
- Pooling layer를 통과해도 채널 수는 변경되지 않는다.
- Pooling의 종류
- Max pooling
- Average pooling

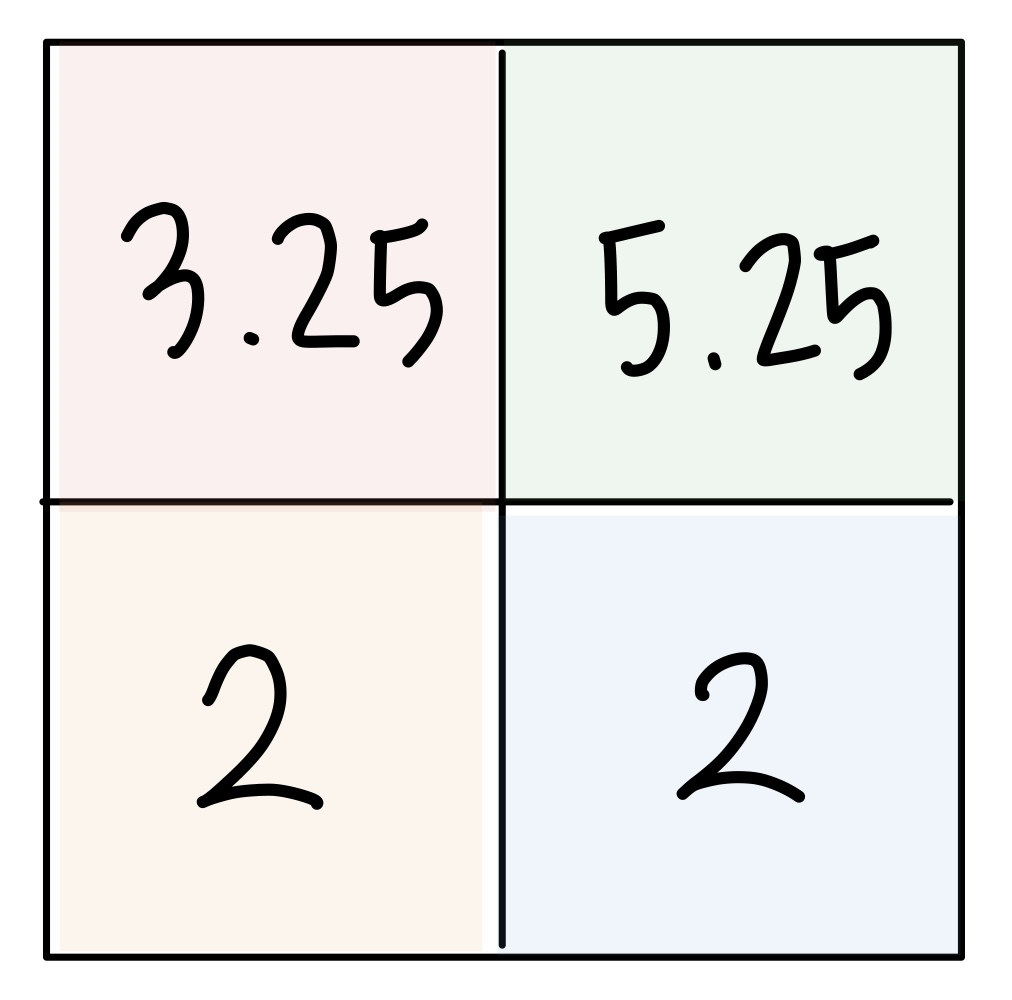
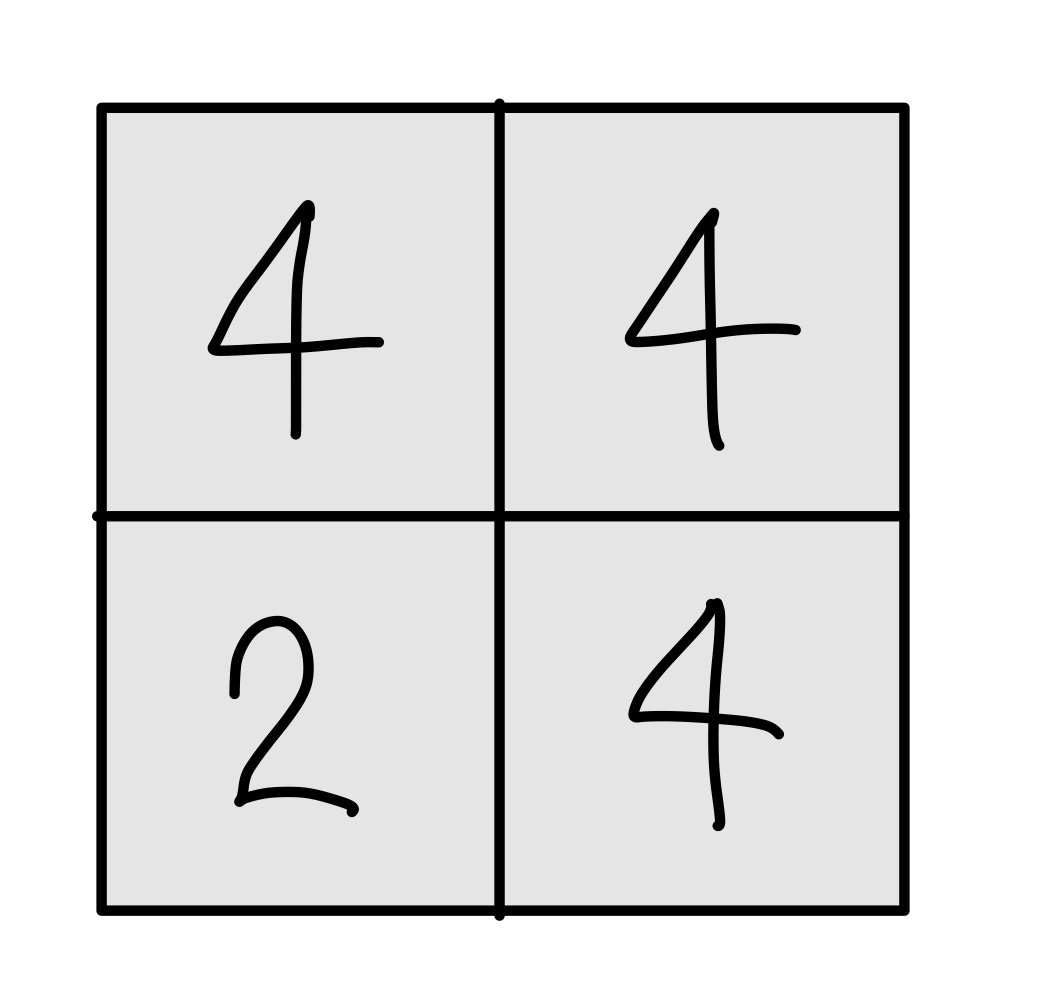
- 일반적으로 위의 사진처럼 모든 원소가 한 번씩만 처리되도록 stride를 설정한다.
✅ Convolution layer : 이미지의 특징을 찾는 역할
✅ Pooling layer : 특징을 강화하고 모으는 역할
레이어 별 출력 데이터 크기 계산 방법
-
Convolution layer
$OutputHeight = OH = {(H + 2P - FH) \over S } + 1$
$OutputWeight = OW = {(W + 2P - FW) \over S } + 1$
$H$ : 입력 데이터의 높이(세로)
$W$ : 입력 데이터의 폭(가로)
$FH$ : 필터의 높이(세로)
$FW$ : 필터의 폭(가로)
$S$ : stride
$P$ : padding size
➡️ $OH$와 $OW$는 자연수가 되어야 한다.
➡️ 또한 convolution layer 뒤에 pooling layer가 온다면 feature map의 크기는 pooling size의 배수여야 한다.
📌 이러한 조건을 만족하도록 필터의 크기, stride 간격, pooling 크기, padding 크기를 조절해야 한다.
-
Pooling layer
$OutputRowSize = {InputRowSize \over PoolingSize}$
$OutputColumnSize = {InputColumnSize \over PoolingSize}$
e.g) 만약 2x2 pooling layer에 input으로 들어온 이미지 데이터의 높이와 폭이 64 x 128이면, 이 pooling layer의 output feature map의 크기는 32x64이다. (모든 원소가 한 번씩만 처리되어야 하므로 이 때 stride=2)
CNN 구성 예시
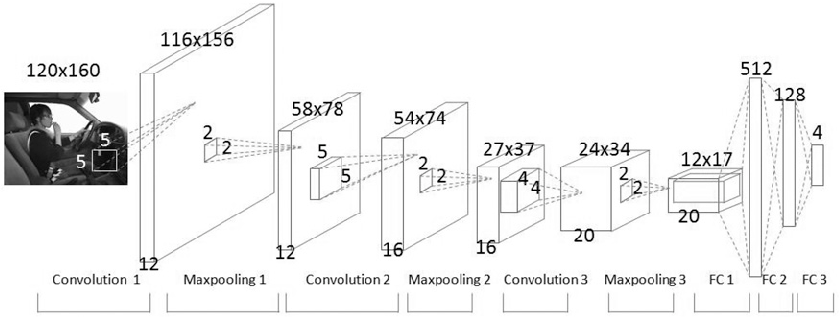
특징 추출 부분 - Convolution layer와 max pooling layer 반복적으로 쌓음
- Conv1 - 5x5 filter 12개 이용
- 2x2 pooling으로 사이즈 1/2로 줄임
-
Conv2 - 5x5 filter 16개 이용
(padding 거쳐서 output 사이즈 54x74가 됨)
- 2x2 pooling으로 사이즈 1/2로 줄임
- Conv3 - 4x4 filter 20개 이용
- 2x2 pooling으로 사이즈 1/2로 줄임
분류 부분 - Fully Connected layer를 적용하고, 마지막 출력층에 Softmax를 적용함
- (121720, 512)
- (512, 128)
- (128, 4)
(이 CNN은 class가 4개인 데이터를 분류하기 위한 모델)