[강화시스터즈 1기] 인공지능과 머신러닝
00. 인공지능과 머신 러닝
인공지능
인공지능 : 인간이 수행하는 지능적인 작업을 자동화하기 위한 도구
- 학습 과정 없이 규칙만으로 하드 코딩된 프로그램부터 스스로 규칙을 학습하는 프로그램을 포함하는 개념
머신 러닝
머신 러닝 : 기계가 특정 테스크를 수행하는 방법을 스스로 학습하기를 기대한다.
앨런 튜링(1912-1954)

메모리와 컴퓨터 개념을 만든 인물이자, 머신 러닝 이론을 처음으로 고안한 인물이다.
“What we want is a machine that can learn from experience, possibility of letting the machine alter its own instructions provides the mechanism for this.”(1947)
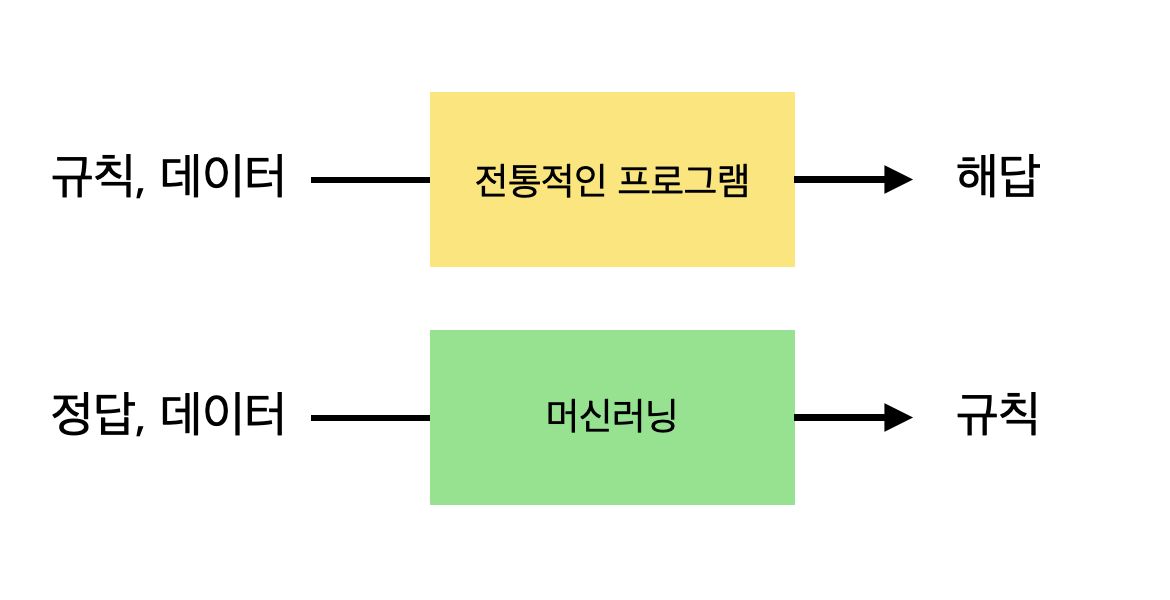
전통적인 프로그램과 머신 러닝
전통적인 방식의 프로그램은 하드 코딩된 규칙과 데이터를 투입하면 답을 뱉어주는 계산 기계다.
반대로 머신 러닝은 데이터와 답을 제공했을 때 스스로 자신의 구조를 변경하며 규칙을 찾아내고자 한다.
머신 러닝의 하위 분야
지도 학습과 비지도 학습
머신 러닝은 학습에서 해답을 제공하는가에 따라 지도 학습과 비지도 학습으로 나뉜다.
-
지도 학습
지도 학습은 학습 과정에서 답이 주어지는 방법론이다.
주어진 답과 예측 값을 비교해 오차를 줄여나가는 방식으로 학습한다.
대표적인 지도 학습 방법론에는 회귀분석, 딥러닝이 있다.
-
비지도 학습
지도 학습과 달리 별도의 답이 주어지지 않는 방법론이다.
비지도 학습은 주어진 데이터 셋 사이의 유사성을 파악해 문제를 해결한다.
대표적인 비지도 학습 방법론에는 군집화, 차원 축소가 있다.
강화학습은 지도 학습 or 비지도 학습?
강화학습은 지도 학습이나 비지도 학습으로 명확히 분류되지 않는다. 강화학습에는 행동에 대한 보상이 존재한다.이 보상은 직접적인 정답이 아니지만, 에이전트의 행동을 유도하는 간접적인 정답의 역할을 수행한다. 따라서 직접적인 정답이 없지만 데이터 그 자체만으로 학습하진 않기에, 지도 학습이나 비지도 학습으로 명확히 분류할 수 없다.
강화학습은 명확하게 정답을 라벨링하기 힘든 상황에서, 보상을 통한 행동 유도로 규칙을 찾게 만든다. 이런 특성은 명확하게 정답을 붙이기 힘든 실생활의 문제들을 학습 가능하게 만들 수 있다는 장점이 있다.